
Heapster是容器集群监控和性能分析工具,天然的支持Kubernetes和CoreOS,Kubernetes有个出名的监控agent—cAdvisor。在每个kubernetes Node上都会运行cAdvisor,它会收集本机以及容器的监控数据(cpu,memory,filesystem,network,uptime),在较新的版本中,K8S已经将cAdvisor功能集成到kubelet组件中。每个Node节点可以直接进行web访问。
cAdvisor web界面访问: http://< Node-IP >:4194cAdvisor也提供Restful API: https://github.com/google/cadv … pi.md
Heapster是一个收集者,将每个Node上的cAdvisor的数据进行汇总,然后导到第三方工具(如InfluxDB)。
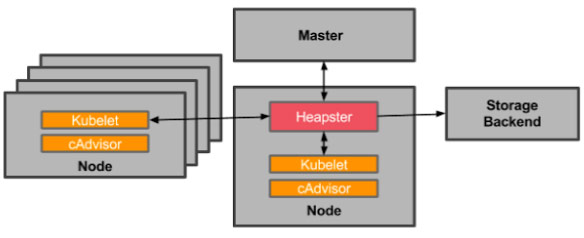
Heapster首先从K8S Master获取集群中所有Node的信息,然后通过这些Node上的kubelet获取有用数据,而kubelet本身的数据则是从cAdvisor得到。所有获取到的数据都被推到Heapster配置的后端存储中,并还支持数据的可视化。现在后端存储 + 可视化的方法,如InfluxDB + grafana。
这里主要介绍Heapster的API使用,及可获取的Metrics;API文档及可用Metrics在官方文档中都介绍的比较齐全。下面用几条测试来解释API使用,获取支持的metrics
curl -L http://:8082/api/v1/model/metrics
列出所有的Nodes支持的metrics
curl -L http://:8082/api/v1/model/nodes/metrics
查看对应Pod的cpu使用率
curl -L http://:8082/api/v1/model/namespaces//pods//metrics/cpu-usage
我们采用Heapster以InfluxDB作为数据存储后端,再配合Grafana的前端进行数据可视化的系统监控方案,进行部署。
镜像制作:Heapster的版本:v0.19.0没有采用最新的Heapster版本,是因为我们使用的Kubernets版本为较旧的v1.0.3,较新的Heapster版本不兼容该K8S版本。Heapster镜像:进入heapster-0.19.0//deploy/docker,使用build.sh进行镜像制作。 该会依赖go环境进行heapster源码编译,所以需要提前安装go环境(go和godep的安装)。InfluxDB和Grafana镜像:这两个镜像的Dockerfile分别在根目录下的对应文件中,只需查看Makefile进行对应的编译制作镜像即可。Dockerfile会依赖一些基础镜像,最好提前下载好。
Heapster容器的运行可以依赖Kubernetes进行部署,也可以单独使用docker命令进行部署。
直接依赖heapster-0.19.0/deploy/kube-config/influxdb/目录下的yaml文件,使用kubectl create -f heapster-0.19.0/deploy/kube-config/influxdb/命令进行部署。
我们没有采用该方式,是考虑到如果K8S和监控系统相互依赖,会导致K8S异常之后,存在监控系统无法使用的隐患。
但是直接使用单独的容器进行部署,也需要考虑到监控容器异常退出了,谁来维护重启?
需要进行权衡?
还需要注意一点:Heapster会使用内存进行数据缓存,容易撑爆内存,导致容器OOM
使用docker命令进行部署的话,需要传入各种参数,该参数可以参考kubernetes部署使用到的yaml文件。
具体命令如下:
docker run -p 8083:8083 -p 8086:8086 --net=host -v /data heapster_influxdb:canary
注:data是数据存储目录,需要考虑数据可持久化,并且能保证容器重启不影响数据。docker run -p 3000:3000 --net=host -e INFLUXDB_SERVICE_URL=http://:8086 -e GF_AUTH_BASIC_ENABLED="false" -e GF_AUTH_ANONYMOUS_ENABLED="true" -e GF_AUTH_ANONYMOUS_ORG_ROLE="Admin" -e GF_SERVER_ROOT_URL=/ -v /var heapster_grafana:canary
docker run -it -p 8082:8082 --net=host heapster:canary --source=kubernetes:http://:8080?inClusterConfig=false\&useServiceAccount=false --sink=influxdb:http://:8086
Heapster命令参考相对较为重要,可以参考官方文档,具体如下:
–source: 指定数据获取源。这里我们指定kube-apiserver即可。后缀参数:inClusterConfig:kubeletPort: 指定kubelet的使用端口,默认10255kubeletHttps: 是否使用https去连接kubelets(默认:false)apiVersion: 指定K8S的apiversioninsecure: 是否使用安全证书(默认:false)auth: 安全认证useServiceAccount: 是否使用K8S的安全令牌–sink: 指定后端数据存储。这里指定influxdb数据库。后缀参数:user: InfluxDB用户pw: InfluxDB密码db: 数据库名secure: 安全连接到InfluxDB(默认:false)withfields: 使用InfluxDB fields(默认:false)。